On Speech Sparsity for Computational Efficiency and Noise Reduction in Hearing Aids
Adrien Llave Simon Leglaive
CentraleSupélec, IETR, France
2021 IEEE annual conference organized by Asia-Pacific Signal and Information Processing Association (APSIPA)
Article | Audio examples | Slides | Bibtex | Acknowledgement
Abstract| Beamforming techniques are widely used in hearing aids to improve the signal-to-noise ratio. In a multi-speaker scenario, it is common to assume that the speech signals associated with each speaker do not overlap in the time-frequency domain. This so-called W-disjoint orthogonality assumption allows us to reduce the complexity of the beamforming algorithm. However, its validity decreases in presence of more than two speakers. In this study, we propose a beamforming algorithm relying on a less restrictive assumption regarding the sparsity of speech signals in the time-frequency domain. Its implications over the noise reduction performance and the computational complexity are discussed and compared with the Linearly Constrained Minimum Variance (LCMV) and the Minimum Variance Distortionless Response (MVDR) beamformers. We show that the proposed algorithm improves the noise reduction performance and reduces the computational cost compared to the LCMV beamformer without increasing the artifacts amount unlike the MVDR beamformer. |
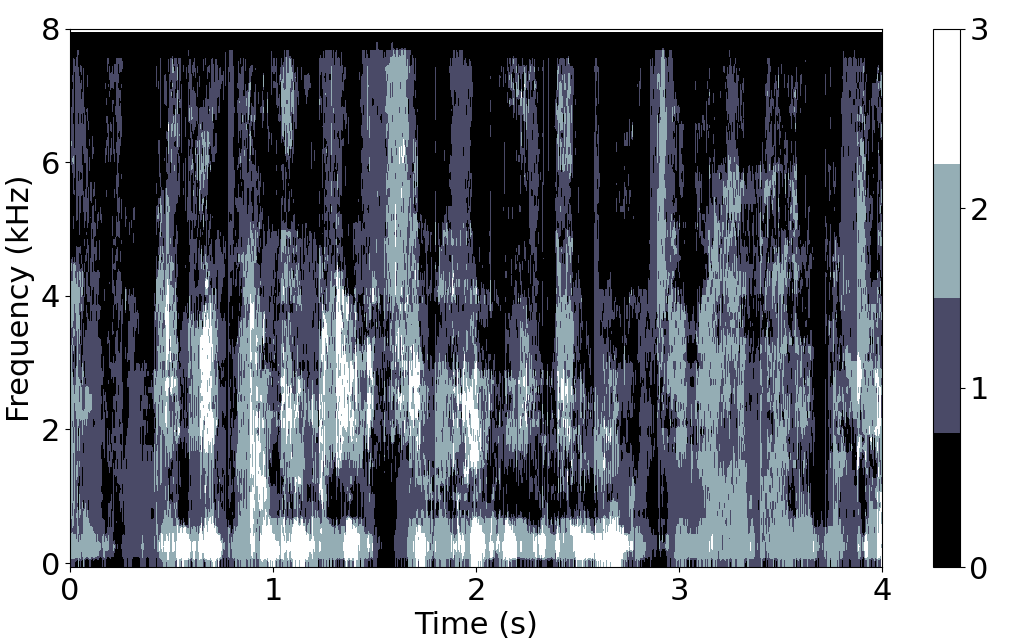 Example of the number of active sources in the STFT domain for a mixture of 3 sentences.
Example of the number of active sources in the STFT domain for a mixture of 3 sentences.
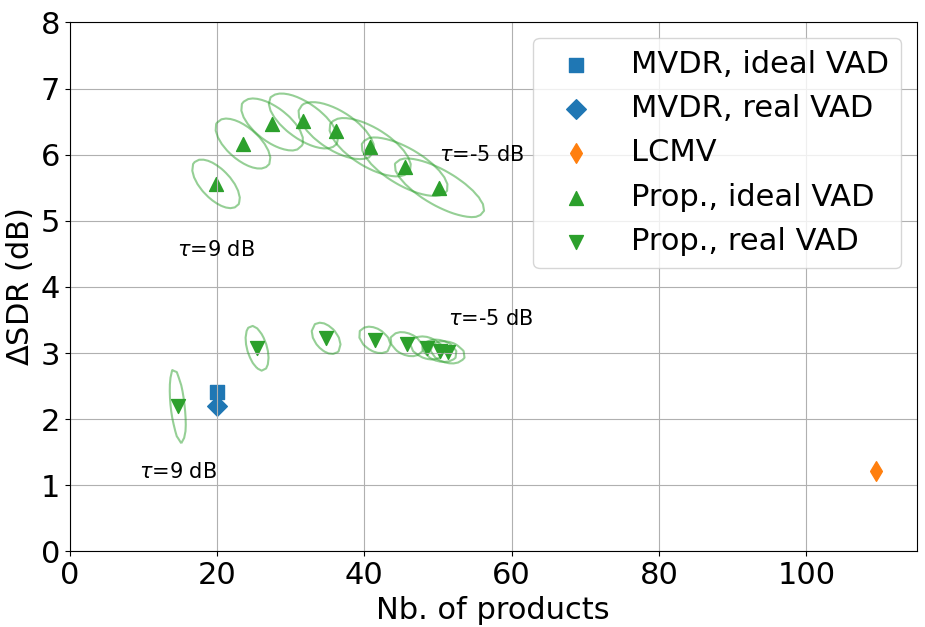 SDR improvement versus computational complexity averaged over the examples for an SNR of 0 dB. The ellipses show the standard deviation isovalue of a 2D gaussian distribution fitted over the results for the proposed algorithm with the VAD threshold ranging from -5 to 9 dB with a 2 dB step.
SDR improvement versus computational complexity averaged over the examples for an SNR of 0 dB. The ellipses show the standard deviation isovalue of a 2D gaussian distribution fitted over the results for the proposed algorithm with the VAD threshold ranging from -5 to 9 dB with a 2 dB step.
|
You can listen to audio examples of an auditory scene composed of three speech sources located on the horizontal plane at -45, 0 and 45°, respectively, and a cafeteria noise at an SNR of 5 dB.
| Ideally clean speech sources | Noisy mixture |
|---|---|
| Speech locations @ azimuths: -45, 0, 45° | |
|---|---|
| Original | |
| MVDR beamformer | |
| LCMV beamformer | |
| Proposed beamformer |
The authors acknowledges the Région Bretagne for funding the HPPA (HRTF pour les prothèses auditives) FEDER project.